Online Transformer RL
Published at Aug 31, 2025
The goal of this project was to see if a simple actor critic could train a transformer from scratch to solve partially observable markov decision processes. While there have been a few works exploring the use of transformers in RL, in fully online settings RNNs remain more common.
I focused on environments that require good use of context, but not very long context so I could fit the entire episode in the back propagation over time. Because of this constraint grid based problems seemed like a good fit because a lot can unfold in the environment in relatively few time-steps.
The results show that transformers can be trained to use context effectively in a reasonable amount of time on consumer hardware with on-policy reinforcement learning.
The model and algorithm are implemented here: https://github.com/gabe00122/jaxrl
Approach
A key idea is to train on entire trajectories in a single update step, so the update can stay on-policy without worrying about initial carry state. I treat each time step as one “token” in the transformer and I consider the last last action taken and last reward received to be part of the observation (shouldn’t the agents always be able to remember what action they took?)
A rollout is collected over multiple parallel agents, using a KV cache to speed up inference.
Because the entire context influences action selection, training on only part of a trajectory would make the data off-policy. Someone could get around this using sliding window attention and recording the KV cache at the beginning of the rollout.
When the rollout is filled
- The advantage and target values are calculated using TD(λ).
- The trajectories are shuffled over the batch dimension but not the timestep dimension.
- The trajectories are split into multiple mini-batches over the batch dimension.
The mini-batch update uses a standard PPO loss function and the adamw or muon optimizer to make a gradient step.
Architecture
Embeddings
The model uses three embeddings:
- Last action — similar to a tied-weight embedding in an LLM, also reused as the actor head
- Last reward — a simple linear projection
- Observation — environment-specific but for grid worlds simply one hotting each tile, flattening and using a single linear projection works well
These embeddings are summed and passed into a stack of transformer layers.
Transformer Layers
- Pre-layer norm
- RoPE
- Grouped-query attention
- Optional sliding-window attention
Outputs
- Actor head — Discrete policy logits
- Value function — includes an extra hidden layer + activation (slightly better than a direct linear projection), if a histogram loss is used then the outputs are value logits
I’ve been testing with 6 transformer layers, a hidden size of 128 and a feed forward size of 768 with a context size of 512. The total parameter count comes out to around 2.3 million parameters.
While I used histogram loss for the value for most of my training there are sometimes catastrophic failure modes if the discretization of the value function doesn’t represent the target value well.
I haven’t deeply evaluated histogram targets with MSE value targets but I think it could have advantages in terms of stability.
Performance
One thing I wondered about was if you could get the number of samples needed to train with PPO using a transformer based model on consumer hardware and I found that it can fairly fast with a small context size!
I’m training on a single 5090 at 2.2 million steps per second! If you only use a single transformer layer this is closer to 10 million steps per second but as I’ll get to later, the model isn’t very effective with only one layer.
Here are a few things that were important to performance
- Both the environments and training code were written in a single end-to-end jitted JAX training loop.
- Using the cudnn backend on nvidia GPU’s via Dot Product Attention
- bfloat16 with float32 accumulation speeds up training and didn’t noticeably hurt performance.
- Using grouped query attention with one kv head and four query heads significantly speeds up training and has a small negative impact on performance.
- Batched inference has a large impact on performance, using 4092 vectorized agents ensured that rollout creation had high algorithmic intensity.
Results
To test memory and context usage, I used a simple 2D grid environment:
- A new grid is generated each episode using multiple octaves of perlin noise.
- The agent must find a random target location.
- Upon reaching the target, the agent gets a reward and is moved to another random location.
- Maximizing rewards requires exploring effectively and remembering the route back using features of the grid.
Observations are given as a small grid view tile types, one hotted, flattened and encoded with a dense layer before being passed to the transformer.
Overall the agents do a great job figuring out where they are and returning to a previous location quickly, but more compute reliably leads to better agents at this problem and I’m sure I have not reached peak performance yet.
Agents in yellow, walls in red and goal in blue. The highlighted range is the observation size.
For some reason the agents always form groups in this environment even though there is no obvious incentive to.
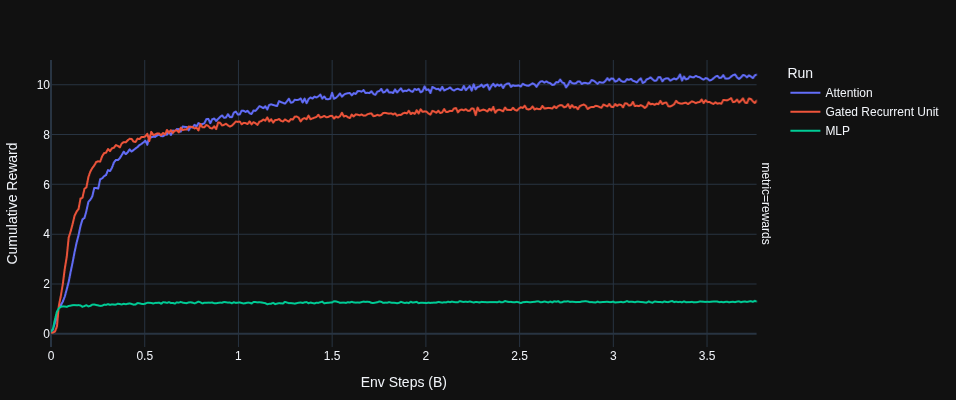
RNNs
I found that if you substitute self attention layers with gru layers and do full back prop through time the model is respectable but only around 1/4th the training speed of a similarly sized transformer with a BPTT length of 512.
Even for RL the lack of parallelism can make training RNNs significantly slower than transformers.
A MLP fails to progress beyond a basic level of reward.
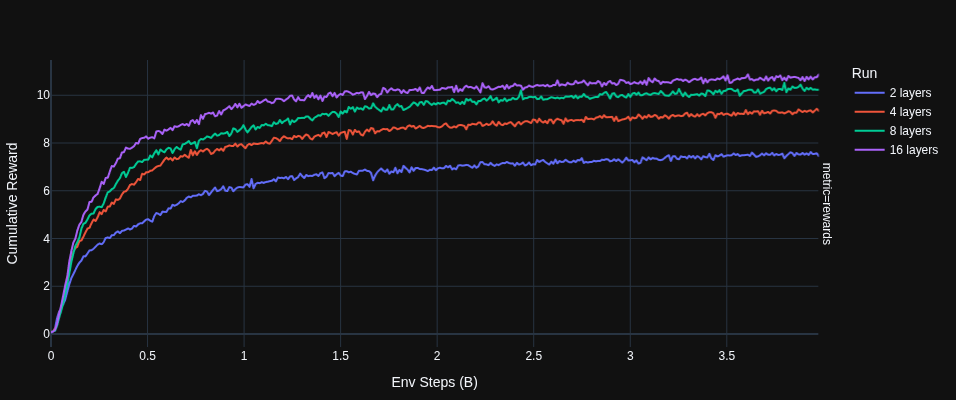
Scaling
The transformer on the grid memory environment seems to have predictable parameter scaling. I found that as you increase the number of layers, sample efficiency predictable improves. Even though smaller networks require less compute the optimal parameter count rises as the compute budget rises.
Craftax
I wanted to test the trainer on a existing environment so I could compare to other implementations, with minimal hyper parameter tuning compared to the custom environment hypers I achieved an average reward of 39 in Craftax.
Despite doing reasonably well at getting some of the easier achievements the model still did a poor job with basic survival actions such as eating and drinking water.
Next Steps
- I could potentially train with a rollout that does not contain an entire episode and stay on policy, this would require sliding window attention and to retain the KV cache used at the beginning of the rollout.
- Multi-environment learning: I want to see if training spatial reasoning in a grid can transfer to other partially observable grid environments by training a single model on multiple environments.
- Exploring linear attention or state space models, these might combine some of the performance benefits of transformers and RNNs.