Memory and Implicit Communication
Published at Apr 9, 2026
The two demos below preview the main result of this post: agents with no explicit communication channel can still use movement and visibility as a signaling mechanism based on their in-context spacial memory.
These agents haven’t been trained on this map, have separate memory and rewards and yet surprisingly quickly they seem to come to a collective decision that they should explore the center of the map even though it is more costly then exploring the outside.
Similarly the rabbit and turtle haven’t been trained on this map and the turtle is so slow exploring all of the corridors would be costly, the rabbit is able to point the turtle down the right hallway by staying in its field of view.
Spatial Memory and Communication
I started this project to explore emergent communication in multi-agent reinforcement learning, but I quickly found that memory was a necessary prerequisite. Agents need memory both to gather information worth communicating and to make use of communicated information later.
Multi-agent environments are naturally partially observable. Not only is the world state hidden, but other agents also have private observations and internal state. If another agent uses memory, then its behavior depends on what it has seen before, not just what it sees now. From your perspective, that memory is part of the hidden state.
This creates a recursive problem: memory helps an agent deal with partial observability, but once one agent has memory, every other agent faces a harder inference problem. They now have to model policies conditioned on latent internal state.
That is why I became interested in memory before communication. In this post, I use “communication” broadly: not just explicit messages, but any observable behavior that changes another agent’s future beliefs or decisions.
Communication and exploration also have a similar structure. Exploration improves your own future decisions by improving your knowledge of the world. Communication improves another agent’s future decisions by changing what they know about the world. If agents have different goals, that change does not have to be helpful. Honest signaling, selective disclosure, and deception are all forms of communication.
What I Built
I wanted to see if model-free RL with a transformer over time could learn something similar to spatial memory and if this spatial memory could be communicated between agents with sufficient self-play. I also wanted to see if training the same model on multiple tasks would lead to task-to-task skill transfer.
This builds on the transformer RL framework described in my previous post. The training framework can be found at mapox-trainer and the environments mapox
The checkpoint shown here was trained jointly on four environments. I focus on two of them because they most clearly expose the role of memory and implicit communication. The other two: a competitive king-of-the-hill game and a predator-prey game-were part of the multitask training mix but deserve separate analysis because the incentives and learned behaviors are qualitatively different.
Cooperative Exploration
To test if agents could share information from their memory when incentives were perfectly aligned I designed a simple asymmetric exploration game
There are two agent types, a fast rabbit and a slow turtle agent. Both agents are rewarded when the turtle reaches the flag location.
- Both agents have separate memory
- Agents have an egocentric field of view highlighted by the shaded square
- Each episode uses a new map from a map generator
- The rabbit’s only effect on the environment is to observe and to be observed by the turtle
- There is no explicit communication channel
Here’s an example episode on the type of map these agents are trained on:
To test generalization I hand-crafted maps to challenge the agents, this is what was used for the first two video demonstrations, the challenge maps are never in the training set. The scouts don’t get distracted by unreachable goal locations. They seem to know the difference between one they can reach and one they can’t get to.
Hand-crafted maps don’t always work, in this one the turtle nearly sees the goal before turning around. I think something about the corridors being close together confused them. Perhaps the scout developed an exploration heuristic where it prefers a certain spacing to get good coverage of the map but this confuses the communication signal between agents.
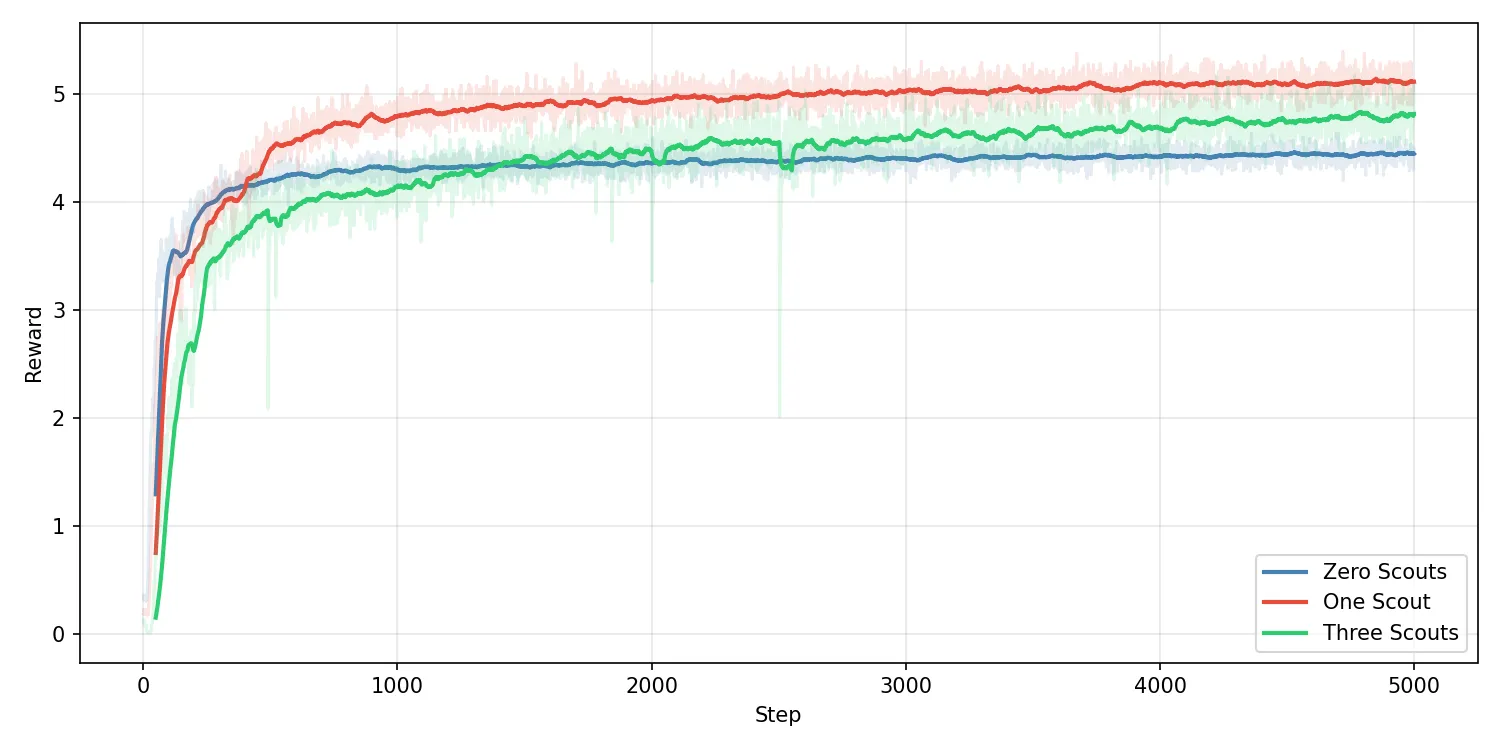
Training on the other environments leads to much better performance than training on the scout environment alone. My theory is the relationship between the scout and the turtle is inherently unstable because they’re both adapting to each other at the same time so it’s a challenging moving target. The other environments help with a core spatial memory ability that benefits this environment but is challenging to learn from this environment alone.
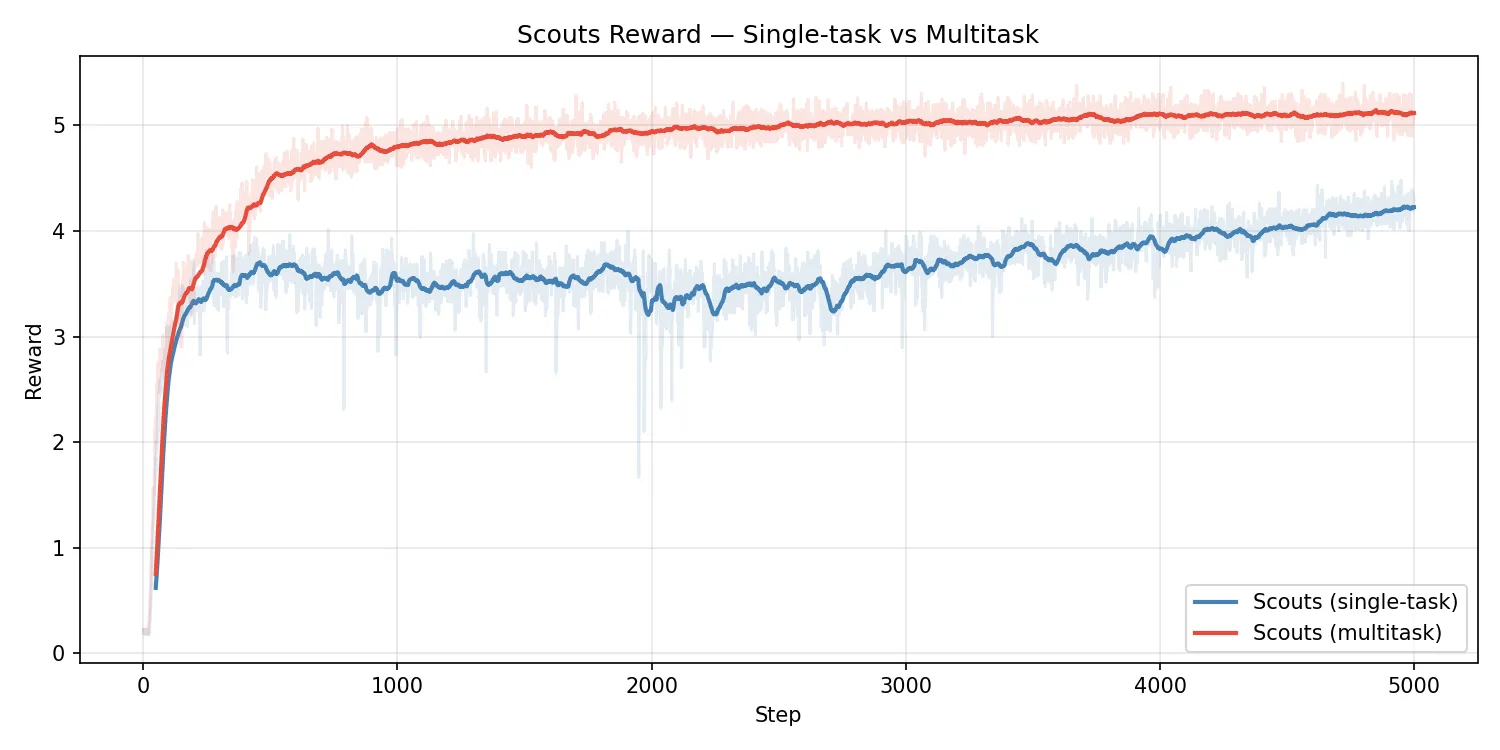
I wondered if scaling up the proportion of the population that were scouts would improve the average reward but this does not seem to be the case. Having one rabbit and one turtle per environment seems to be a sweet spot. I thought that 3 rabbits per turtle would lead to higher average reward but it seems to be lower than just one to one. A turtle with no rabbits performs worse than with one rabbit but better than the one to one ratio without multitask training. With optimal training more rabits should lead to strictly better exploration and therefor reward, the fact that it does not suggests a shortcoming in my current training approach.
Find & Return
Initially this environment was designed to test a single agent’s spatial memory but interesting things happen when you add multiple agents into the environment together.
- Agents spawn in a random location on a randomized map and must find the flag location
- When agents find the flag they are given a reward and teleported to a random new location, this is still a single episode
- Walls can be destroyed but causes a timeout to the agent that destroyed it
- Agents can see each other but otherwise don’t interact directly
Agents seem to group up consistently despite no shared reward. The simplest explanation is that this helps them dig walls faster but even when wall digging is disabled the grouping behavior persists.
You can lead the agents around if you manually control one, they don’t always follow you but if you act decisively it’s more likely that they will. Sometimes the agent in the rear of the group initiates the group to change course.
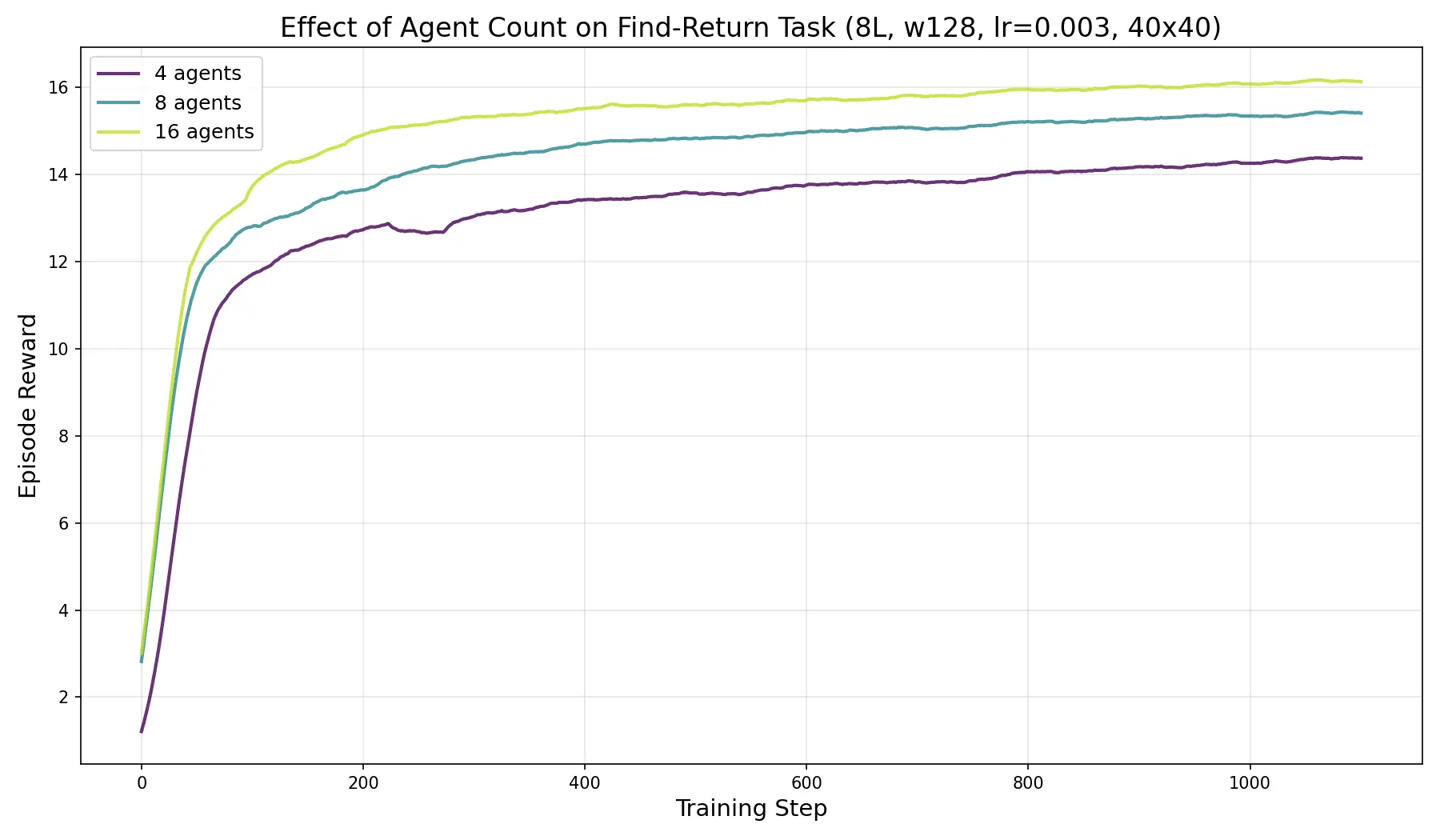
Contrary to the cooperative exploration environment, in this environment individual reward scales up reliably with agent count. This strongly suggests they are gaining a benefit from being in groups and the benefit goes up as the groups become larger.
Conclusion
This work barely scratches the surface, it shows that memory and self-play alone is sufficient for some basic agent to agent signaling but particularly in the cooperative exploration environment I think there’s a much higher ceiling for how well agents could coordinate. I believe there’s a strong possibility that more specialized multiagent techniques would lead to much better performance and I would invite anyone interested to use these environments as a benchmark and try to improve on these results.
A natural follow-up is to study trust and deception directly. I want to build environments where agents have private, role-dependent goals: some aligned with the group, others opposed to it. In that setting, communication is no longer just about sharing information, but about judging reliability and hidden intent.